Carl Friedrich Bolz是一位在伦敦国王大学任职的研究员, 他沉迷于动态语言的实现及优化等领域而不可自拔. 他是PyPy/RPython的核心开发者之一, 于此同时, 他也在为Prolog, Racket, Smalltalk, PHP和Ruby等语言贡献代码.
开篇
面向对象编程是目前被广泛使用的一种编程范式, 这种编程范式也被大量现代编程语言所支持. 虽然大部分语言给程序猿提供了相似的面向对象的机制, 但是如果深究细节的话, 还是能发现它们之间还是有很多不同的. 大部分的语言的共同点在于都拥有对象处理和继承机制, 而对于类来说的话, 并不是每种语言都完美支持它. 比如对于Self或者JavaScript这样的基于原型继承的语言来说, 其实是没有类这个概念的, 他们的继承行为都是在对象之间所产生的.
深入了解不同语言的对象模型是一件非常有意思的事儿, 这样我们可以去欣赏不同的编程语言的相似性. 不得不说, 这样的经历可以在我们学习新的语言的时候, 利用上我们已有的经验, 以便于我们快速的掌握它.
这篇文章将会带领你实现一套简单的对象模型. 首先我们将实现一个简单的类与其实例, 并能够通过这个实例去访问一些方法. 这是被诸如Simula 67, malltalk等早期面向对象语言所采用的面向对象模型. 然后我们会一步步的扩展这个模型, 你可以看到接下来两步会为你展现不同语言的模型设计思路. 然后最后一步是来优化我们的对象模型的性能. 最终我们所得到的模型并不是哪一门真实存在的语言所采用的模型. 不过, 硬是要说的话, 你可以把我们得到的最终模型视为一个低配版的Python对象模型.
这篇文章里所展现的对象模型都是基于Python实现的. 代码在Python2.7以及Python3.4上都可以完美运行. 为了让大家更好的了解模型里的设计哲学, 本文也为我们所设计的对象模型准备了单元测试, 这些测试代码可以利用py.test或者nose来运行.
讲真, 用 Python 来作为对象模型的实现语言并不是一个好的选择. 一般而言, 语言的虚拟机都是基于 C/C++ 这样更为贴近底层的语言来实现的, 同时在实现中需要非常注意很多的细节, 以保证其执行效率. 不过, Python 这样非常简单的语言能让我们将主要精力都放在不同的行为表现上, 而不是纠结于实现细节不可自拔.
基础方法模型
我们将以 Smalltalk 中的实现的非常简单的对象模型来开始讲解我们的对象模型. Smalltalk 是一门由施乐帕克研究中心下属的 Alan Kay 所带领的小组在 70 年代所开发出的一门面向对象语言. 它普及了面向对象编程, 同时在今天的编程语言中依然能看到当时它所包含的很多特性. 在 Smalltalk 核心设计原则之一便是:“万物皆对象”. Smalltalk 最广为人知的继承者是 Ruby, 一门使用类似 C 语言语法的同时保留了 Smalltalk 对象模型的语言.
在这一部分中, 我们所实现的对象模型将包含类, 实例, 属性的调用及修改, 方法的调用, 同时允许子类的存在. 开始前, 先声明一下, 这里的类都是有他们自己的属性和方法的普通的类
友情提示:在这篇文章中, “实例”代表着“不是类的对象”的含义.
一个非常好的习惯就是优先编写测试代码, 以此来约束具体实现的行为. 本文所编写的测试代码由两个部分组成. 第一部分由常规的 Python 代码组成, 可能会使用到 Python 中的类及其余一些更高级的特性. 第二部分将会用我们自己建立的对象模型来替代 Python 的类.
在编写测试代码时, 我们需要手动维护常规的 Python 类和我们自建类之间的映射关系. 比如, 在我们自定类中将会使用 obj.read_attr("attribute") 来作为 Python 中的 obj.attribute 的替代品. 在现实生活中, 这样的映射关系将由语言的编译器/解释器来进行实现.
在本文中, 我们还对模型进行了进一步简化, 这样看起来我们实现对象模型的代码和和编写对象中方法的代码看起来没什么两样. 在现实生活中, 这同样是基本不可能的, 一般而言, 这两者都是由不同的语言实现的.
首先, 让我们来编写一段用于测试读取求改对象字段的代码:
1 | def test_read_write_field(): |
在上面这个测试代码中包含了我们必须实现的三个东西. Class 以及 Instance 类分别代表着我们对象中的类以及实例. 同时这里有两个特殊的类的实例:OBJECT 和 TYPE. OBJECT 对应的是作为 Python 继承系统起点的 object 类(在 Python 2.x 版本中, 实际上是有两套类系统, 一套被统称为 new style class 的新式类, 一套被称为 old style class 的经典类, object 是 new style class 的基类). TYPE 对应的是 Python 类型系统中的 type .
为了给 Class 以及 Instance 类的实例提供通用操作支持, 这两个类都会从 Base 类这样提供了一系列方法的基础类中进行继承并实现:
1 | class Base(object): |
Base 实现了对象类的储存, 同时也使用了一个字典来保存对象字段的值. 现在, 我们需要去实现 Class 以及 Instance 类. 在Instance 的构造器中将会完成类的实例化以及 fields 和 dict 初始化的操作. 换句话说, Instance 只是 Base 的子类, 同时并不会为其添加额外的方法.
Class 的构造器将会接受类名、基础类、类字典、以及元类这样几个操作. 对于类来讲, 上面几个变量都会在类初始化的时候由用户传递给构造器. 同时构造器也会从它的基类那里获取变量的默认值. 不过这个点, 我们将在下一章节进行讲述.
1 | class Instance(Base): |
同时, 你可能注意到这点, 类依旧是一种特殊的对象, 他们间接的从 Base 中继承. 因此, 类也是一个特殊类的特殊实例, 这样的很特殊的类叫做:元类.
现在, 我们可以顺利通过我们第一组测试. 不过这里, 我们还没有定义 Type 以及 OBJECT 这样两个 Class 的实例. 对于这些东西, 我们将不会按照 Smalltalk 的对象模型进行构建, 因为 Smalltalk 的对象模型对于我们来说太过于复杂. 作为替代品, 我们将采用 ObjVlisp1 的类型系统, Python 的类型系统从这里吸收了不少东西.
在 ObjVlisp 的对象模型中, OBJECT 以及 TYPE 是交杂在一起的. OBJECT 是所有类的母类, 意味着 OBJECT 没有母类. TYPE 是 OBJECT 的子类. 一般而言, 每一个类都是 TYPE 的实例. 在特定情况下, TYPE 和 OBJECT 都是 TYPE 的实例. 不过, 程序猿可以从 TYPE 派生出一个类去作为元类:
1 | # set up the base hierarchy as in Python (the ObjVLisp model) |
为了去编写一个新的元类, 我们需要自行从 TYPE 进行派生. 不过在本文中我们并不会这么做, 我们将只会使用 TYPE 作为我们每个类的元类.
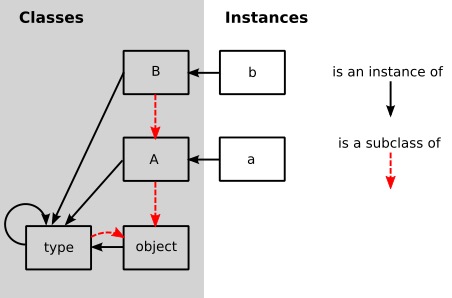
Figure - Inheritance
好了, 现在第一组测试已经完全通过了. 现在让我们来看看第二组测试, 我们将会在这组测试中测试对象属性读写是否正常. 这段代码还是很好写的.
1 | def test_read_write_field_class(): |
isinstance 检查
到目前为止, 我们还没有将对象有类这点特性利用起来. 接下来的测试代码将会自动的实现 isinstance .
1 | def test_isinstance(): |
我们可以通过检查 cls 是不是 obj 类或者它自己的超类来判断 obj 对象是不是某些类 cls 的实例. 通过检查一个类是否在一个超类链上工作, 来判断一个类是不是另一个类的超类. 如果还有其余类存在于这个超类链上, 那么这些类也可以被称为是超类. 这个包含了超类和类本身的链条, 被称之为方法解析顺序(简称MRO). 它很容易以递归的方式进行计算:
1 | class Class(Base): |
好了, 在修改代码后, 测试就完全能通过了
方法调用
前面所建立的对象模型中还缺少了方法调用这样的重要特性. 在本章我们将会建立一个简单的继承模型.
1 | def test_callmethod_simple(): |
为了找到调用对象方法的正确实现, 我们现在开始讨论类对象的方法解析顺序. 在 MRO 中我们所寻找到的类对象字典中第一个方法将会被调用:
1 | class Class(Base): |
在完成 Base 类中 callmethod 实现后, 可以通过上面的测试.
为了保证函数参数传递正确, 同时也确保我们事先的代码能完成方法重载的功能, 我们可以编写下面这段测试代码, 当然结果是完美通过测试:
1 | def test_callmethod_subclassing_and_arguments(): |
基础属性模型
现在最简单版本的对象模型已经可以开始工作了, 不过我们还需要去不断的改进. 这一部分将会介绍基础方法模型和基础属性模型之间的差异. 这也是 Smalltalk 、 Ruby 、 JavaScript 、 Python 和 Lua 之间的核心差异.
基础方法模型将会按照最原始的方式去调用方法:
result = obj.f(arg1, arg2)
基础属性模型将会将调用过程分为两步:寻找属性, 以及返回执行结果:
method = obj.f
result = method(arg1, arg2)
你可以在接下来的测试中体会到前文所述的差异:
1 | def test_bound_method(): |
我们可以按照之前测试代码中对方法调用设置一样的步骤去设置属性调用, 不过和方法调用相比, 这里面发生了一些变化. 首先, 我们将会在对象中寻找与函数名对应的方法名. 这样一个查找过程结果被称之为已绑定的方法, 具体来说就是, 这个结果一个绑定了方法与具体对象的特殊对象. 然后这个绑定方法会在接下来的操作中被调用.
为了实现这样的操作, 我们需要修改 Base.read_attr 的实现. 如果在实例字典中没有找到对应的属性, 那么我们需要去在类字典中查找. 如果在类字典中查找到了这个属性, 那么我们将会执行方法绑定的操作. 我们可以使用一个闭包来很简单的模拟绑定方法. 除了更改 Base.read_attr 实现以外, 我们也可以修改 Base.callmethod 方法来确保我们代码能通过测试.
1 | class Base(object): |
其余的代码并不需要修改.
元对象协议
除了常规的类方法之外, 很多动态语言还支持特殊方法. 有这样一些方法在调用时是由对象系统调用而不是使用常规调用. 在 Python 中你可以看到这些方法的方法名用两个下划线作为开头和结束的, 比如 __init__ . 特殊方法可以用于重载一些常规操作, 同时可以提供一些自定义的功能. 因此, 它们的存在可以告诉对象模型如何自动的处理不同的事情. Python 中相关特殊方法的说明可以查看这篇文档.
元对象协议这一概念由 Smalltalk 引入, 然后在诸如 CLOS 这样的通用 Lisp 的对象模型中也广泛的使用这个概念. 这个概念包含特殊方法的集合(注:这里没有查到 coined3 的梗, 请校者帮忙参考).
在这一章中, 我们将会为我们的对象模型添加三个元调用操作. 它们将会用来对我们读取和修改对象的操作进行更为精细的控制. 我们首先要添加的两个方法是 __getattr__ 和 __setattr__, 这两个方法的命名看起来和我们 Python 中相同功能函数的方法名很相似.
自定义属性读写操作
__getattr__ 方法将会在属性通过常规方法无法查找到的情况下被调用, 换句话说, 在实例字典、类字典、父类字典等等对象中都找不到对应的属性时, 会触发该方法的调用. 我们将传入一个被查找属性的名字作为这个方法的参数. 在早期的 Smalltalk4 中这个方法被称为 doesNotUnderstand .
在 __setattr__ 这里事情可能发生了点变化. 首先我们需要明确一点的是, 设置一个属性的时候通常意味着我们需要创建它, 在这个时候, 在设置属性的时候通常会触发 __setattr__ 方法. 为了确保 __setattr__ 的存在, 我们需要在 OBJECT 对象中实现 __setattr__ 方法. 这样最基础的实现完成了我们向相对应的字典里写入属性的操作. 这可以使得用户可以将自己定义的 __setattr__ 委托给 OBJECT.__setattr__ 方法.
针对这两个特殊方法的测试用例如下所示:
1 | def test_getattr(): |
为了通过测试, 我们需要修改下 Base.read_attr 以及 Base.write_attr 两个方法:
1 | class Base(object): |
获取属性的过程变成调用 __getattr__ 方法并传入字段名作为参数, 如果字段不存在, 将会抛出一个异常. 请注意 __getattr__ 只能在类中调用(Python 中的特殊方法也是这样), 同时需要避免这样的 self.read_attr("__getattr__") 递归调用, 因为如果 __getattr__ 方法没有定义的话, 上面的调用会造成无限递归.
对属性的修改操作也会像读取一样交给 __setattr__ 方法执行. 为了保证这个方法能够正常执行, OBJECT 需要实现 __setattr__ 的默认行为, 比如:
1 | def OBJECT__setattr__(self, fieldname, value): |
OBJECT.__setattr__ 的具体实现和之前 write_attr 方法的实现有着相似之处. 在完成这些修改后, 我们可以顺利的通过我们的测试.
描述符协议
在上面的测试中, 我们频繁的在不同的温标之间切换, 不得不说, 在执行修改属性操作的时候这样真的很蛋疼, 所以我们需要在 __getattr__ 和 __setattr__ 中检查所使用的的属性的名称为了解决这个问题, 在 Python 中引入了描述符协议的概念.
我们将从 __getattr__ 和 __setattr__ 方法中获取具体的属性, 而描述符协议则是在属性调用过程结束返回结果时触发一个特殊的方法. 描述符协议可以视为一种可以绑定类与方法的特殊手段, 我们可以使用描述符协议来完成将方法绑定到对象的具体操作. 除了绑定方法, 在 Python 中描述符最重要的几个使用场景之一就是 staticmethod、 classmethod 和 property.
在接下来一点文字中, 我们将介绍怎么样来使用描述符进行对象绑定. 我们可以通过使用 __get__ 方法来达成这一目标, 具体请看下面的测试代码:
1 | def test_get(): |
__get__ 方法将会在属性查找完后被 FahrenheitGetter 实例所调用. 传递给 __get__ 的参数是查找过程结束时所处的那个实例.
实现这样的功能倒是很简单, 我们可以很简单的修改 _is_bindable 和 _make_boundmethod 方法:
1 | def _is_bindable(meth): |
好了, 这样简单的修改能保证我们通过测试了. 之前关于方法绑定的测试也能通过了, 在 Python 中 __get__ 方法执行完了将会返回一个已绑定方法对象.
在实践中, 描述符协议的确看起来比较复杂. 它同时还包含用于设置属性的 __set__ 方法. 此外, 你现在所看到我们实现的版本是经过一些简化的. 请注意, 前面 _make_boundmethod 方法调用 __get__ 是实现级的操作, 而不是使用 meth.read_attr('__get__') . 这是很有必要的, 因为我们的对象模型只是从 Python 中借用函数和方法, 而不是展示 Python 的对象模型. 进一步完善模型的话可以有效解决这个问题.
实例优化
这个对象模型前面三个部分的建立过程中伴随着很多的行为变化, 而最后一部分的优化工作并不会伴随着行为变化. 这种优化方式被称为 map ,广泛存在在可以自举的语言虚拟机中. 这是一种最为重要对象模型优化手段:在 PyPy , 诸如 V8 现代 JavaScript 虚拟机中得到应用(在 V8 中这种方法被称为 hidden classes).
这种优化手段基于如下的观察:到目前所实现的对象模型中, 所有实例都使用一个完整的字典来储存他们的属性. 字典是基于哈希表进行实现的, 这将会耗费大量的内存. 在很多时候, 同一个类的实例将会拥有同样的属性, 比如, 有一个类 Point , 它所有的实例都包含同样的属性 x y.
Map 优化利用了这样一个事实. 它将会将每个实例的字典分割为两个部分. 一部分存放可以在所有实例中共享的属性名. 然后另一部分只存放对第一部分产生的 Map 的引用和存放具体的值. 存放属性名的 map 将会作为值的索引.
我们将为上面所述的需求编写一些测试用例, 如下所示:
1 | def test_maps(): |
注意, 这里测试代码的风格和我们之前的才是代码看起不太一样. 之前所有的测试只是通过已实现的接口来测试类的功能. 这里的测试通过读取类的内部属性来获取实现的详细信息, 并将其与预设的值进行比较. 这种测试方法又被称之为白盒测试.
p1 的包含 attrs 的 map 存放了 x 和 y 两个属性, 其在 p1 中存放的值分别为 0 和 1. 然后创建第二个实例 p2 , 并通过同样的方法网同样的 map 中添加同样的属性. 换句话说, 如果不同的属性被添加了, 那么其中的 map 是不通用的.
Map 类长下面这样:
1 | class Map(object): |
Map 类拥有两个方法, 分别是 get_index 和 next_map . 前者用于查找对象储存空间中的索引中查找对应的属性名称. 而在新的属性添加到对象中时应该使用后者. 在这种情况下, 不同的实例需要用 next_map 计算不同的映射关系. 这个方法将会使用 next_maps 来查找已经存在的映射. 这样, 相似的实例将会使用相似的 Map 对象.
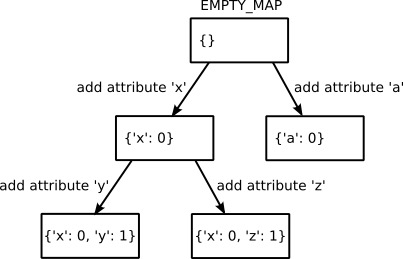
Figure - Map transitions
使用 map 的 Instance 实现如下:
1 | class Instance(Base): |
现在这个类将给 Base 类传递 None 作为字段字典, 那是因为 Instance 将会以另一种方式构建存储字典. 因此它需要重载 _read_dict 和 _write_dict . 在实际操作中, 我们将重构 Base 类, 使其不在负责存放字段字典. 不过眼下, 我们传递一个 None 作为参数就足够了.
在一个新的实例创建之初使用的是 EMPTY_MAP , 这里面没有任何的对象存放着. 在实现 _read_dict 后, 我们将从实例的 map 中查找属性名的索引, 然后映射相对应的储存表.
向字段字典写入数据分为两种情况. 第一种是现有属性值的修改, 那么就简单的在映射的列表中修改对应的值就好. 而如果对应属性不存在, 那么需要进行 map 变换(如上面的图所示一样), 将会调用 next_map 方法, 然后将新的值存放入储存列表中.
你肯定想问, 这种优化方式到底优化了什么?一般而言, 在具有很多相似结构实例的情况下能较好的优化内存. 但是请记住, 这不是一个通用的优化手段. 有些时候代码中充斥着结构不同的实例之时, 这种手段可能会耗费更大的空间.
这是动态语言优化中的常见问题. 一般而言, 不太可能找到一种万能的方法去优化代码, 使其更快, 更节省空间. 因此, 具体情况具体分析, 我们需要根据不同的情况去选择优化方式.
在 Map 优化中很有意思的一点就是, 虽然这里只有花了内存占用, 但是在 VM 使用 JIT 技术的情况下, 也能较好的提高程序的性能. 为了实现这一点, JIT 技术使用映射来查找属性在存储空间中的偏移量. 然后完全除去字典查找的方式.
潜在扩展
扩展我们的对象模型和引入不同语言的设计选择是一件非常容易的事儿. 这里给出一些可能的方向:
最简单的是添加更多的特殊方法方法, 比如一些
__init__,__getattribute__,__set__这样非常容易实现和有趣的方法.扩展模型支持多重继承. 为了实现这一点, 每一个类都需要一个父类列表. 然后
Class.method_resolution_order需要进行修改, 以便支持方法查找. 一个简单的 MRO 计算规则可以使用深度优先原则. 然后更为复杂的可以采用C3 算法, 这种算法能更好的处理菱形继承结构所带来的一些问题.一个更为疯狂的想法是切换到原型模式, 这需要消除类和实例之间的差别.
总结
面向对象编程语言设计的核心是其对象模型的细节. 编写一些简单的对象模型是一件非常简单而且有趣的事情. 你可以通过这种方式来了解现有语言的工作机制, 并且深入了解面向对象语言的设计原则. 编写不同的对象模型验证不同对象的设计思路是一个非常棒的方法. 你也不在需要将注意力放在其余一些琐碎的事情上, 比如解析和执行代码.
这样编写对象模型的工作在实践中也是非常有用的. 除了作为实验品以外, 它们还可以被其余语言所使用. 这种例子有很多:比如 GObject 模型, 用 C 语言编写, 在 GLib 和 其余 Gonme 中得到使用, 还有就是用 JavaScript 实现的各类对象模型.